class: right, bottom
Machine Learning for Urban Analytics
Nikhil Kaza
Department of City & Regional Planning
University of North Carolina at Chapel Hill
updated: 2022-01-22
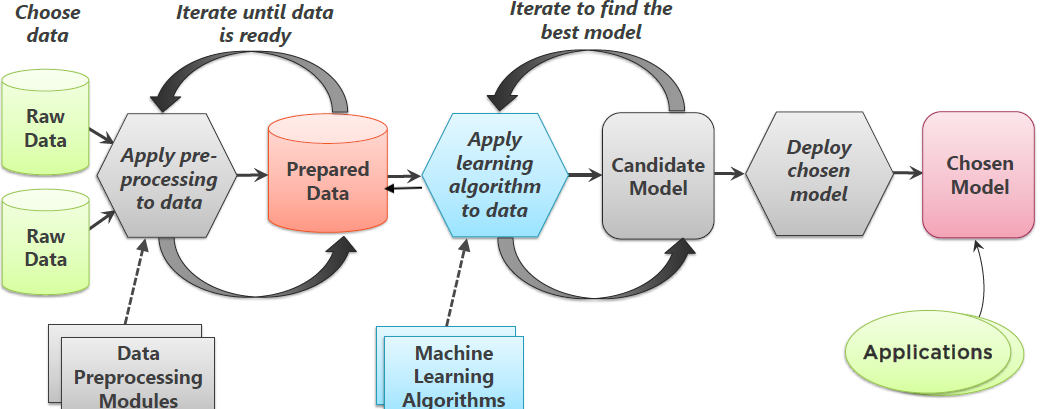
| # What is Machine Learning ? |
 |
The purpose of Machine Learning
- Mostly for Prediction…
- Classification (Categories of objects e.g. spam/not spam; median strip /side walk/road, default/ prepayment / Current)
- Regression (Continous variables, e.g. volume of water consumption/ energy use )
- Not the same as statistical inference such as linear regression.
### OK. What kinds of prediction?
- Local governments: Traffic congestion
- Google: What ads to show
- Amazon: What products to buy
- Insurance: Risk based on prior claims
- UNC: Sakai use to identify students in need of intervention.
Different Terms
- Prediction
- Projection
- Forecast
- Scenarios
What do you think the differences are?
The central dogma of prediction
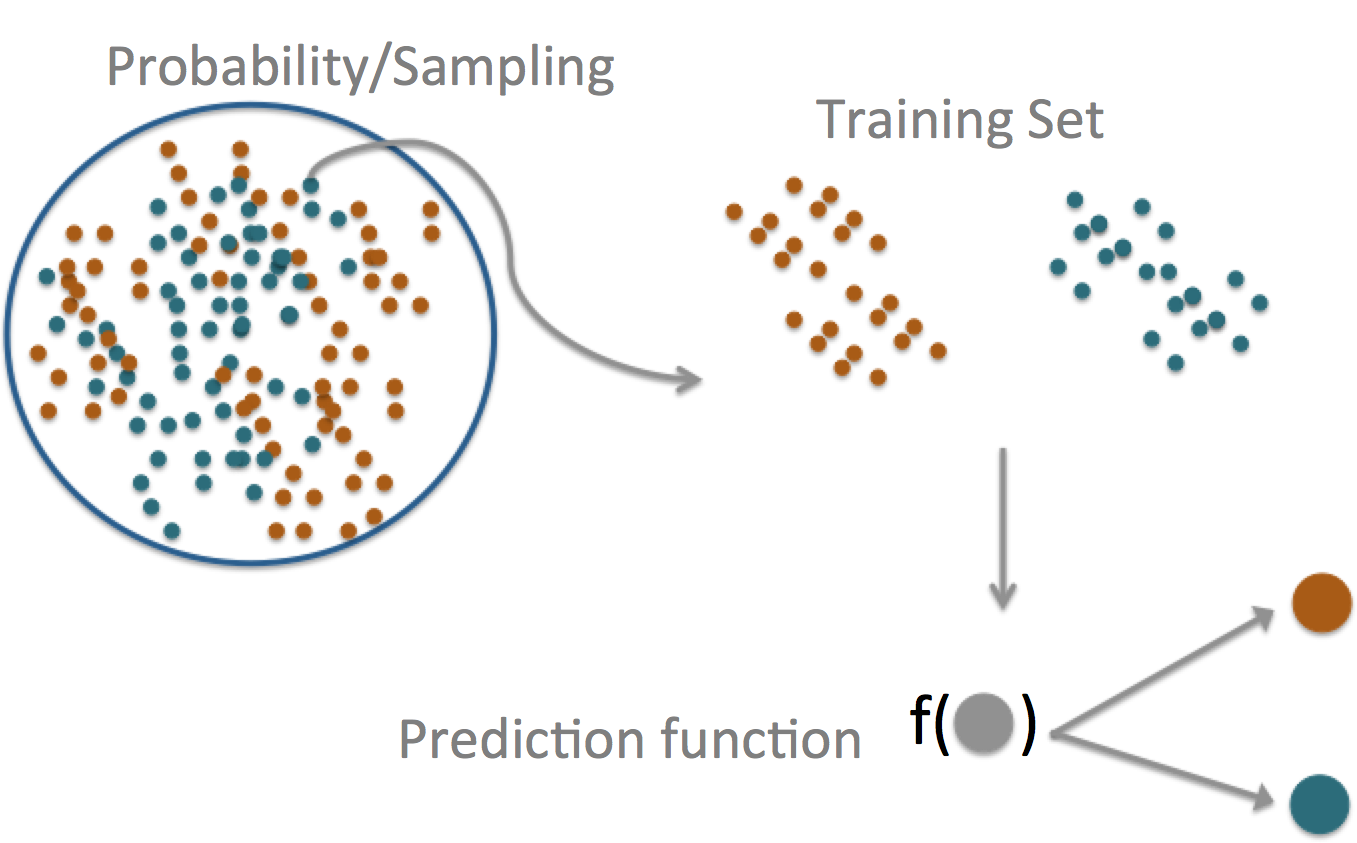
Components of a predictor
SPAM Example
Start with a general question
Can I automatically detect emails that are SPAM that are not?
Make it concrete
Can I use quantitative characteristics of the emails to classify them as SPAM/HAM?
SPAM Example
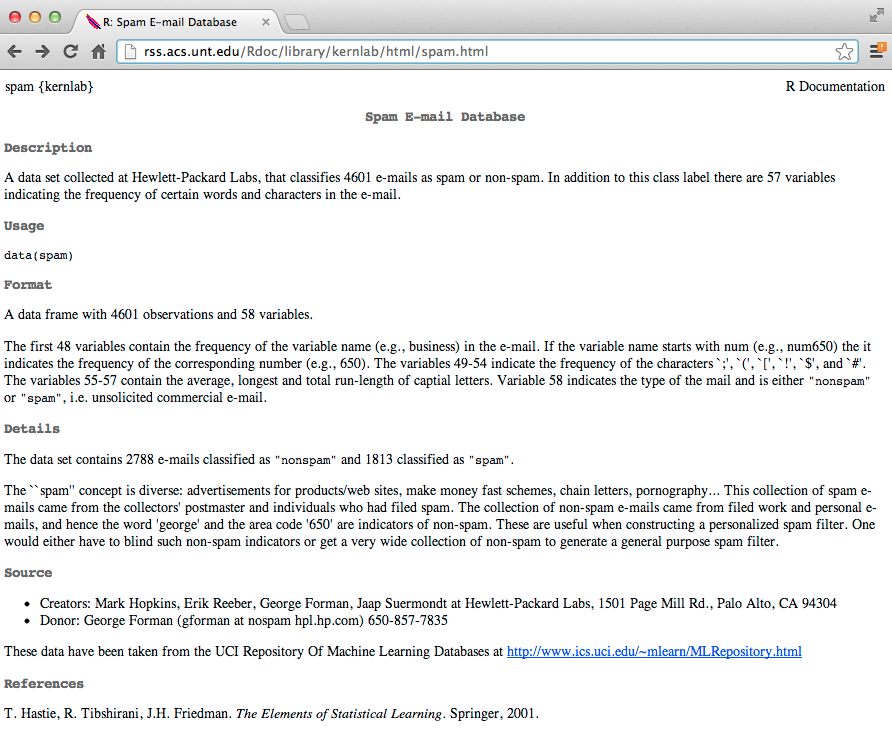
http://rss.acs.unt.edu/Rdoc/library/kernlab/html/spam.html
SPAM Example
Dear Jeff,
Can you send me your address so I can send you the invitation?
Thanks,
Ben
SPAM Example
Dear Jeff,
Can send me your address so I can send the invitation?
Thanks,
Ben
Frequency of you \(= 2/17 = 0.118\)
SPAM Example
library(kernlab)
data(spam)
str(spam)## 'data.frame': 4601 obs. of 58 variables:
## $ make : num 0 0.21 0.06 0 0 0 0 0 0.15 0.06 ...
## $ address : num 0.64 0.28 0 0 0 0 0 0 0 0.12 ...
## $ all : num 0.64 0.5 0.71 0 0 0 0 0 0.46 0.77 ...
## $ num3d : num 0 0 0 0 0 0 0 0 0 0 ...
## $ our : num 0.32 0.14 1.23 0.63 0.63 1.85 1.92 1.88 0.61 0.19 ...
## $ over : num 0 0.28 0.19 0 0 0 0 0 0 0.32 ...
## $ remove : num 0 0.21 0.19 0.31 0.31 0 0 0 0.3 0.38 ...
## $ internet : num 0 0.07 0.12 0.63 0.63 1.85 0 1.88 0 0 ...
## $ order : num 0 0 0.64 0.31 0.31 0 0 0 0.92 0.06 ...
## $ mail : num 0 0.94 0.25 0.63 0.63 0 0.64 0 0.76 0 ...
## $ receive : num 0 0.21 0.38 0.31 0.31 0 0.96 0 0.76 0 ...
## $ will : num 0.64 0.79 0.45 0.31 0.31 0 1.28 0 0.92 0.64 ...
## $ people : num 0 0.65 0.12 0.31 0.31 0 0 0 0 0.25 ...
## $ report : num 0 0.21 0 0 0 0 0 0 0 0 ...
## $ addresses : num 0 0.14 1.75 0 0 0 0 0 0 0.12 ...
## $ free : num 0.32 0.14 0.06 0.31 0.31 0 0.96 0 0 0 ...
## $ business : num 0 0.07 0.06 0 0 0 0 0 0 0 ...
## $ email : num 1.29 0.28 1.03 0 0 0 0.32 0 0.15 0.12 ...
## $ you : num 1.93 3.47 1.36 3.18 3.18 0 3.85 0 1.23 1.67 ...
## $ credit : num 0 0 0.32 0 0 0 0 0 3.53 0.06 ...
## $ your : num 0.96 1.59 0.51 0.31 0.31 0 0.64 0 2 0.71 ...
## $ font : num 0 0 0 0 0 0 0 0 0 0 ...
## $ num000 : num 0 0.43 1.16 0 0 0 0 0 0 0.19 ...
## $ money : num 0 0.43 0.06 0 0 0 0 0 0.15 0 ...
## $ hp : num 0 0 0 0 0 0 0 0 0 0 ...
## $ hpl : num 0 0 0 0 0 0 0 0 0 0 ...
## $ george : num 0 0 0 0 0 0 0 0 0 0 ...
## $ num650 : num 0 0 0 0 0 0 0 0 0 0 ...
## $ lab : num 0 0 0 0 0 0 0 0 0 0 ...
## $ labs : num 0 0 0 0 0 0 0 0 0 0 ...
## $ telnet : num 0 0 0 0 0 0 0 0 0 0 ...
## $ num857 : num 0 0 0 0 0 0 0 0 0 0 ...
## $ data : num 0 0 0 0 0 0 0 0 0.15 0 ...
## $ num415 : num 0 0 0 0 0 0 0 0 0 0 ...
## $ num85 : num 0 0 0 0 0 0 0 0 0 0 ...
## $ technology : num 0 0 0 0 0 0 0 0 0 0 ...
## $ num1999 : num 0 0.07 0 0 0 0 0 0 0 0 ...
## $ parts : num 0 0 0 0 0 0 0 0 0 0 ...
## $ pm : num 0 0 0 0 0 0 0 0 0 0 ...
## $ direct : num 0 0 0.06 0 0 0 0 0 0 0 ...
## $ cs : num 0 0 0 0 0 0 0 0 0 0 ...
## $ meeting : num 0 0 0 0 0 0 0 0 0 0 ...
## $ original : num 0 0 0.12 0 0 0 0 0 0.3 0 ...
## $ project : num 0 0 0 0 0 0 0 0 0 0.06 ...
## $ re : num 0 0 0.06 0 0 0 0 0 0 0 ...
## $ edu : num 0 0 0.06 0 0 0 0 0 0 0 ...
## $ table : num 0 0 0 0 0 0 0 0 0 0 ...
## $ conference : num 0 0 0 0 0 0 0 0 0 0 ...
## $ charSemicolon : num 0 0 0.01 0 0 0 0 0 0 0.04 ...
## $ charRoundbracket : num 0 0.132 0.143 0.137 0.135 0.223 0.054 0.206 0.271 0.03 ...
## $ charSquarebracket: num 0 0 0 0 0 0 0 0 0 0 ...
## $ charExclamation : num 0.778 0.372 0.276 0.137 0.135 0 0.164 0 0.181 0.244 ...
## $ charDollar : num 0 0.18 0.184 0 0 0 0.054 0 0.203 0.081 ...
## $ charHash : num 0 0.048 0.01 0 0 0 0 0 0.022 0 ...
## $ capitalAve : num 3.76 5.11 9.82 3.54 3.54 ...
## $ capitalLong : num 61 101 485 40 40 15 4 11 445 43 ...
## $ capitalTotal : num 278 1028 2259 191 191 ...
## $ type : Factor w/ 2 levels "nonspam","spam": 2 2 2 2 2 2 2 2 2 2 ...SPAM Example
table(spam$type)| nonspam | spam |
|---|---|
| 2788 | 1813 |
SPAM Example
plot(density(spam$your[spam$type=="nonspam"]),
col="blue",main="",xlab="Frequency of 'your'")
lines(density(spam$your[spam$type=="spam"]),col="red")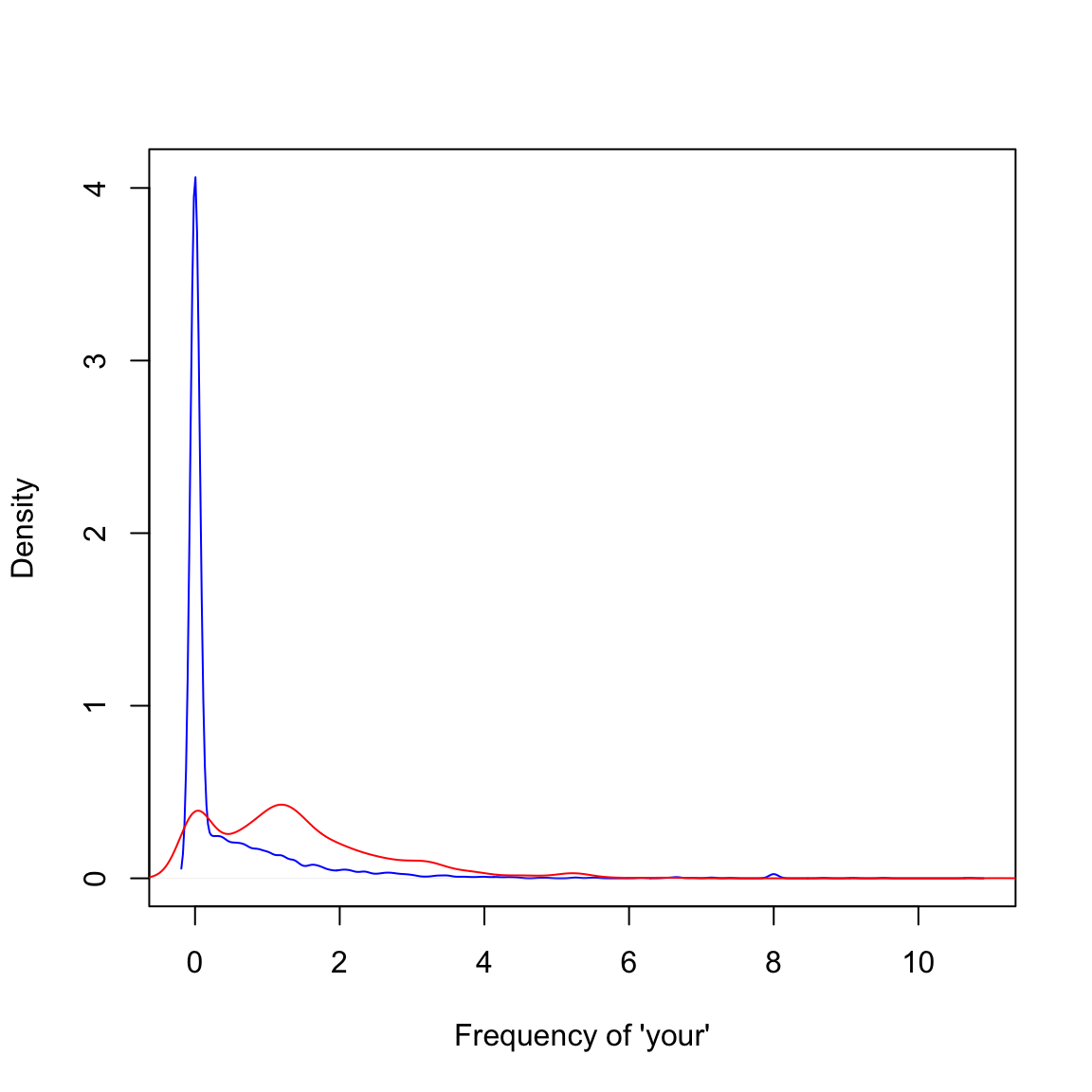
SPAM Example
Our algorithm
- Find a value \(C\).
- frequency of ‘your’ \(>\) C predict “spam”
SPAM Example
plot(density(spam$your[spam$type=="nonspam"]),
col="blue",main="",xlab="Frequency of 'your'")
lines(density(spam$your[spam$type=="spam"]),col="red")
abline(v=0.5,col="black")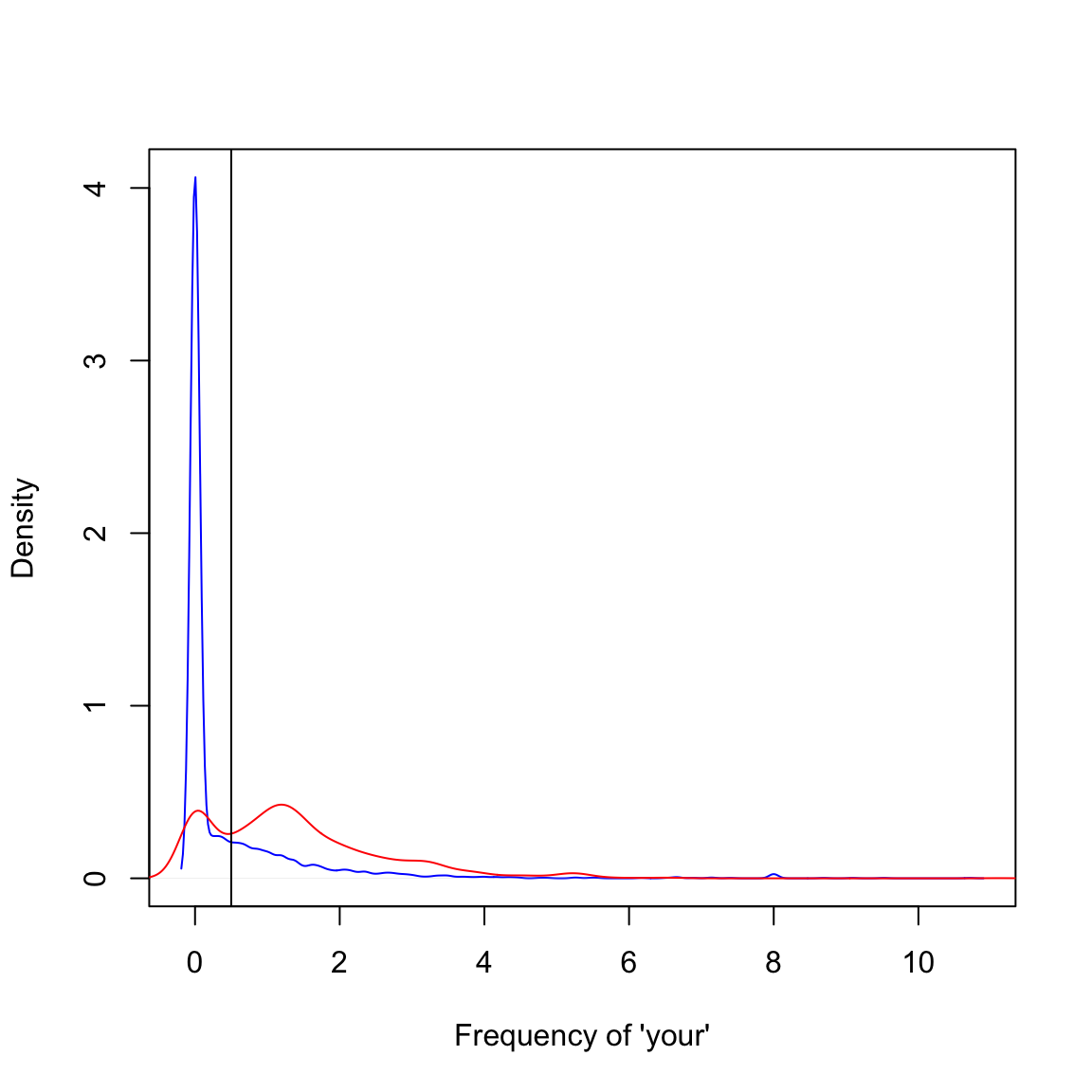
SPAM Example
prediction <- ifelse(spam$your > 0.5,"spam","nonspam")
table(prediction,spam$type)/length(spam$type)| nonspam | spam | |
|---|---|---|
| nonspam | 0.4590306 | 0.1017170 |
| spam | 0.1469246 | 0.2923278 |
Accuracy \(\approx 0.459 + 0.292 = 0.751\)
Bike Sharing
- General Q: Can you predict which stations will need to be restocked with bikes at different times of the day?
- How can you use neighborhood characterstics (demographics, economics, proxmity to other stations) and time of day, day of the week, season, weather etc. to predict number of open slots on bike stations?
Urban Sprawl & Environmental Impacts
- General Q: Can you predict number of bad air quality days from urban form characteristics?
- Can urban landscape metrics and other demographic characteristics predict bad air quality days in a year?
Urban Form & Healthy Behaviours
- General Q: How does urban form characteristics relate to healthy outcomes?
- How does street density, intersection density, activity density etc. impact residents’ healthy behaviours (healthy food consumption, exercise etc.)?
Energy Conservation & Mortgage Risks
- General Q: Should we reward households with conservation proclivities with a break on mortgage interest rates?
- Is the choice to buy energy star appliances and houses in infill urban areas correlated with lower default/prepayment rate?
Mode Choice
- General Q: Can we predict household transportation mode choice?
- Given the weather, cost of travel, cost of parking etc. what is the likelihood that a household will choose to drive vs. taking public transit.
Experimental Design
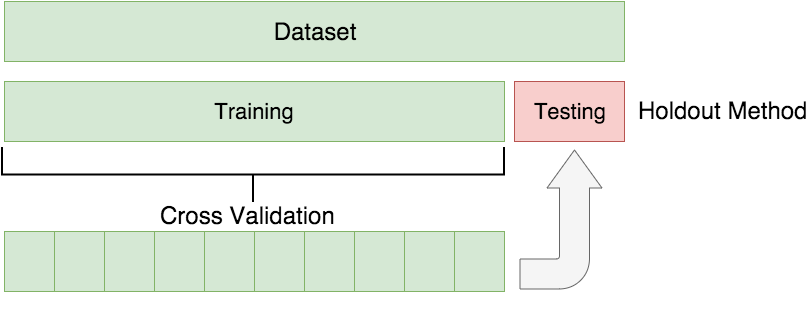
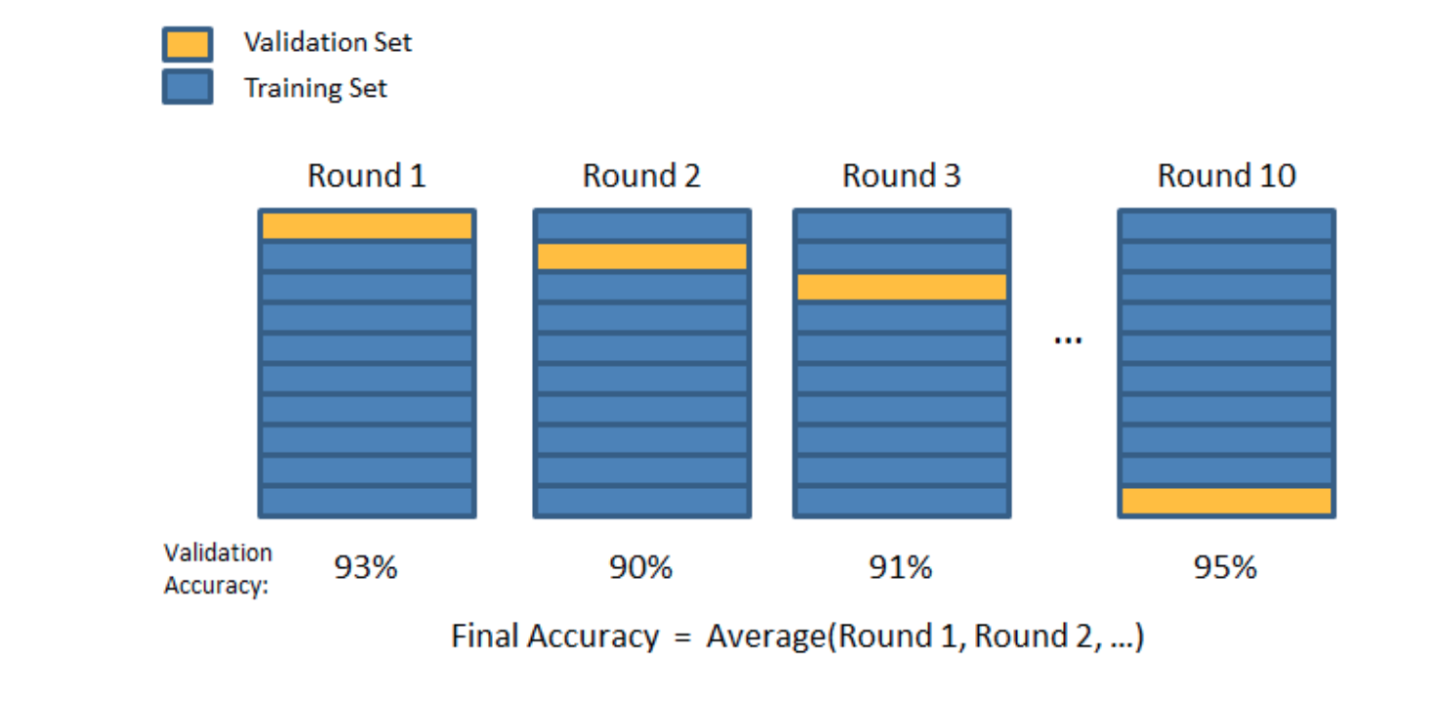

Logistic Regression (Misnomer)

.footnote[http://dataaspirant.com/2017/03/02/how-logistic-regression-model-works/]



And lots more…
![]()
class: right, bottom, inverse
Some Terminology

Bootstrap aggregating (bagging)
- Resample cases and recalculate predictions
- Average or majority vote
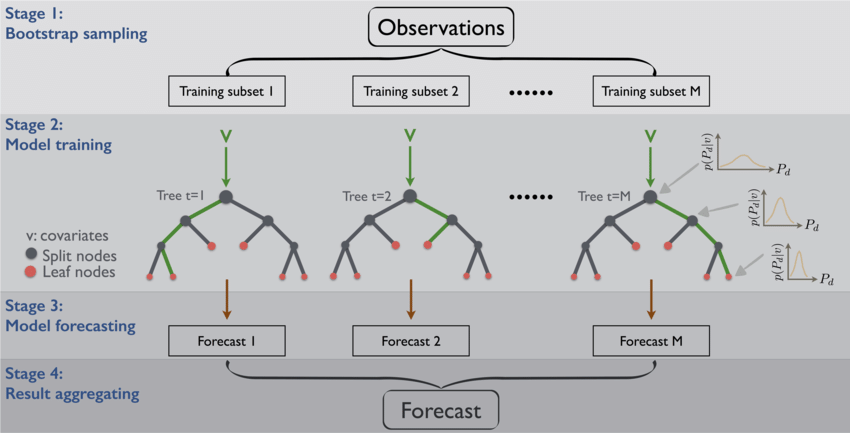
.footnote[ list()]
Boosting
- Create a model
- Focus on the errors of the model and create another model
- Continue this process until no improvement occurs
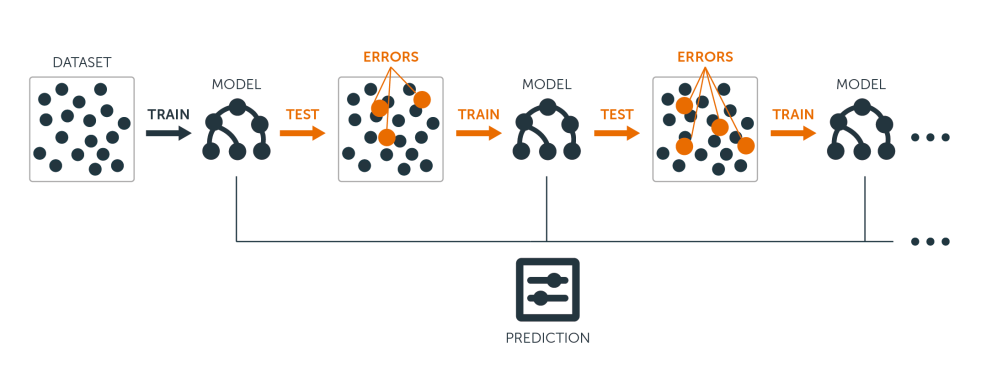
.footnote[https://blog.bigml.com/2017/03/14/introduction-to-boosted-trees/]
| # Boosting Explained |
 |
| .footnote[https://medium.com/mlreview/gradient-boosting-from-scratch-1e317ae4587d] |
Boosting Explained
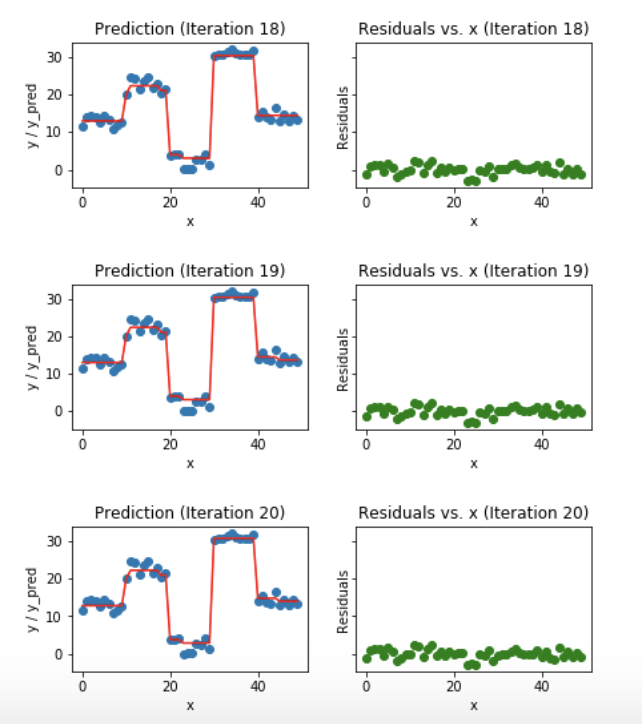
.footnote[https://medium.com/mlreview/gradient-boosting-from-scratch-1e317ae4587d]
| ## Basic terms |
| In general, Positive = identified and negative = rejected. Therefore: |
| True positive (TP) = correctly identified (e.g. Real buildings identified as buildings by the model.) |
| False positive (FP) = incorrectly identified (e.g. Real non-buildings identified as buildings) |
| True negative (TN) = correctly rejected (e.g. Real non-buildings identified as non-buildings by the model) |
| False negative (FN) = incorrectly rejected (e.g. Real buildings identified as roads by the model) |
| http://en.wikipedia.org/wiki/Sensitivity_and_specificity |
Accuracy Metrics
- Mean squared error (or root mean squared error)
- Continuous data, sensitive to outliers
- Median absolute deviation
- Continuous data, often more robust
- Sensitivity (recall): \(TP/(TP+FN)\)
- If you want few missed positives (e.g. identify as many buildings as possible, even if you misidentify some non-buildings as buildings)
- Specificity: \(TN/(TN+FP)\)
- If you want few negatives called positives (e.g. identify more buildings correctly, even if you miss some true buildings )
- Accuracy \((TP+TN)/(TP + TN + FP + FN)\)
- Weights false positives/negatives equally
- Concordance
- One example is kappa
- Predictive value of a positive (precision): \(TP/(TP +FP)\)
- When the prevalance is low (e.g. identify a rare class of a ‘tent city’ in US cities)
| # Conclusion |
 |
Practical Advice
- Focus on the importance of the problem
- Try simple models first
- Much of machine learning is about trying to create good features (variables); Models are secondary
- Scale the features to have similar values (sale price in millions, sq.ft in 1000s don’t work well)
- Ideally you want these features to be minimally correlated
- Some algorithms requires lots of training data. Focus on creating good labelled data. Share it with others